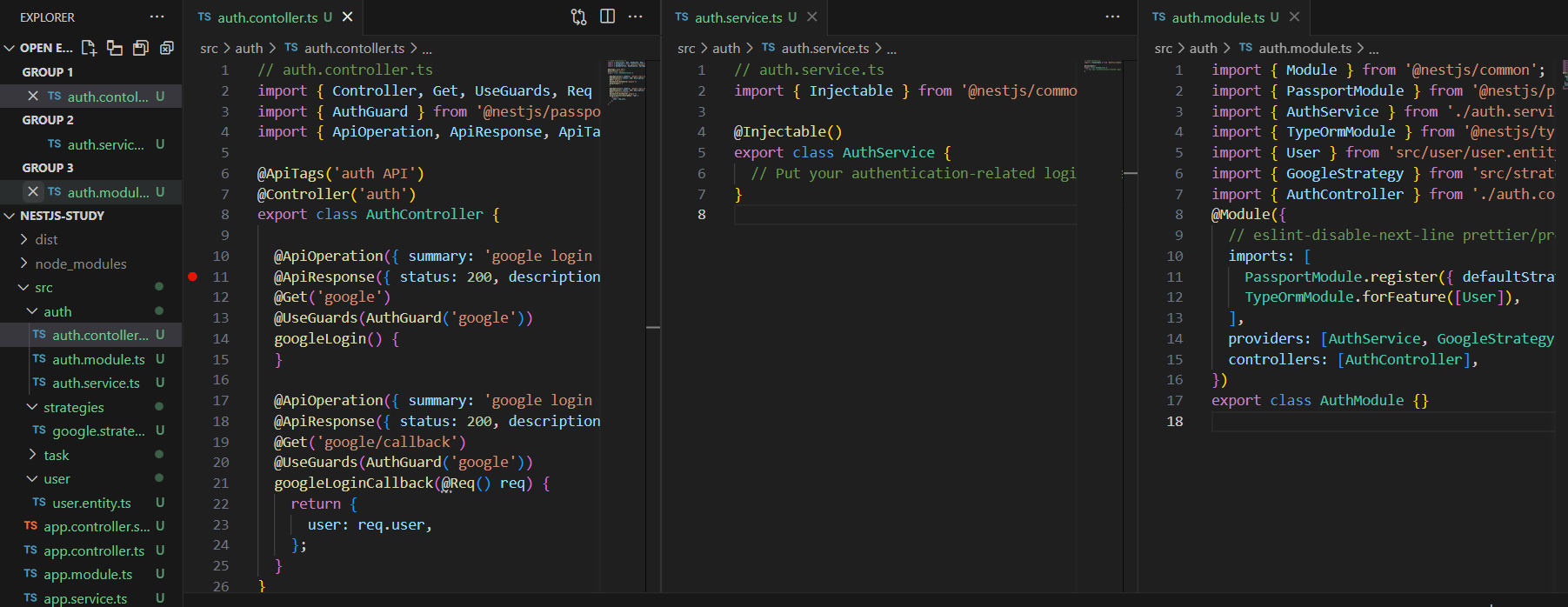
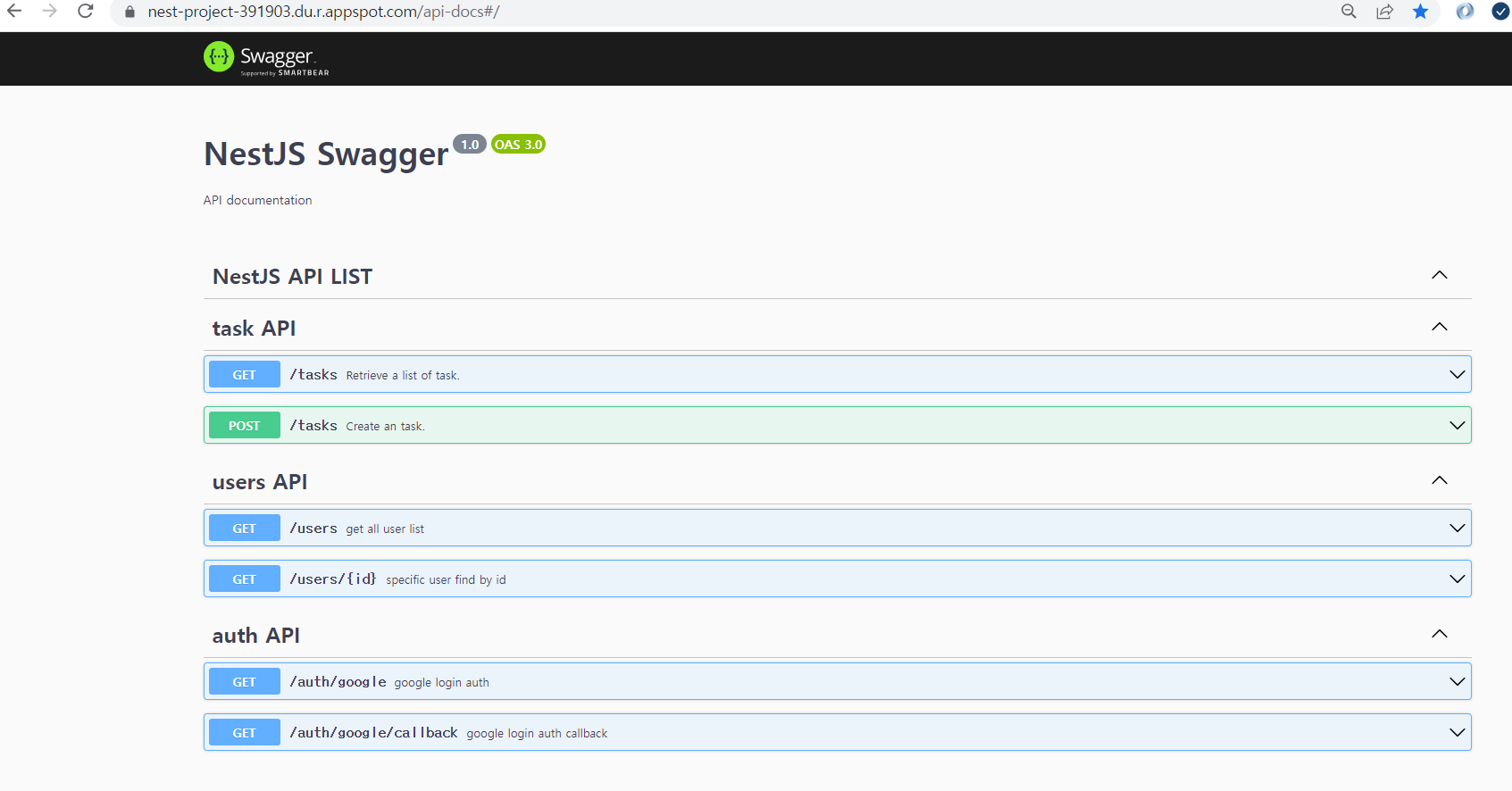
해당 토이 프로젝트는 아래와 같은 기술을 사용할 것이다.
- Reactjs, Typescript, Tailwindcss
- Opentdb API(퀴즈 API)
- Google Cloud Translation API
먼저 프로젝트를 구성해보자.
1. 아래 명령어를 입력한다.
1 2 3 4 | # 리액트 앱 설치 $ npx create-react-app react-ts-quiz-app --template typescript $ cd react-ts-quiz-app $ npm start | cs |
2. 서버가 정상적으로 뜨는지 확인한다.

3. tailwind css를 적용해보자.
https://tailwindcss.com/docs/guides/create-react-app
Install Tailwind CSS with Create React App - Tailwind CSS
Setting up Tailwind CSS in a Create React App project.
tailwindcss.com
위 설명대로 따라하면 된다.
1 2 3 | # tailwindcss 설치 $ npm install -D tailwindcss $ npx tailwindcss init | cs |
제대로 설치 되었다면 아래와 같이 css가 적용된 화면이 나타날것이다.
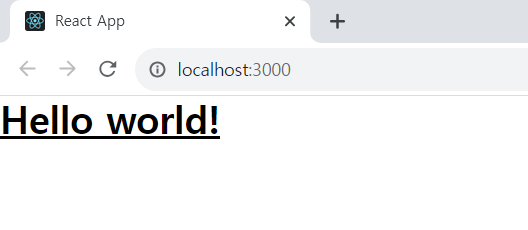
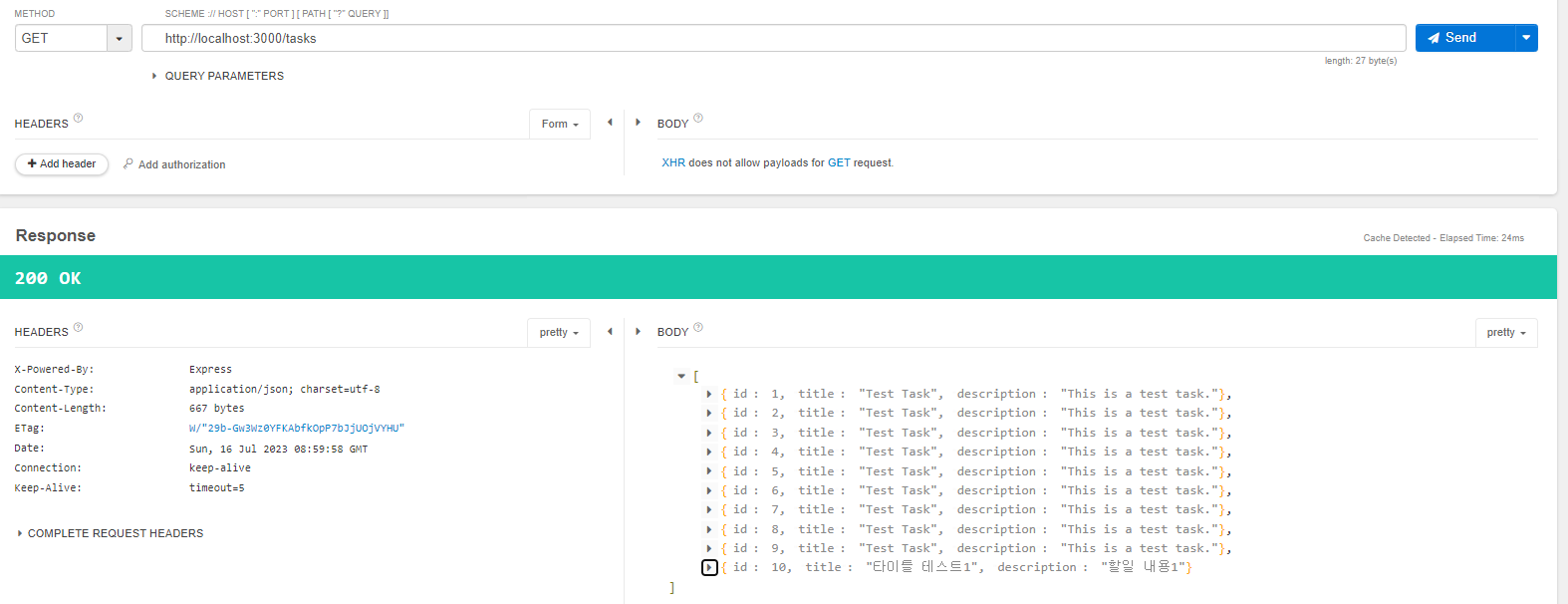
4. 퀴즈 API 데이터를 가져오자.
퀴즈 데이터는 오픈 API인 Open Trivia DB 에서 가져올 것이다.
Open Trivia DB
Free to use, user-contributed trivia questions!
opentdb.com
퀴즈 카테고리, 타입, 난이도, 정답, 오답 등의 json 데이터를 확인가능하다.
https://opentdb.com/api.php?amount=10

그런데 문제가 생겼다. json 데이터가 모두 영어 데이터이다.
영어 json 데이터 를 한글로 번역하면 좋을 것 같다.
구글 번역 API를 사용할 것이다.
5. 구글 클라우드 콘솔에 접속한다.
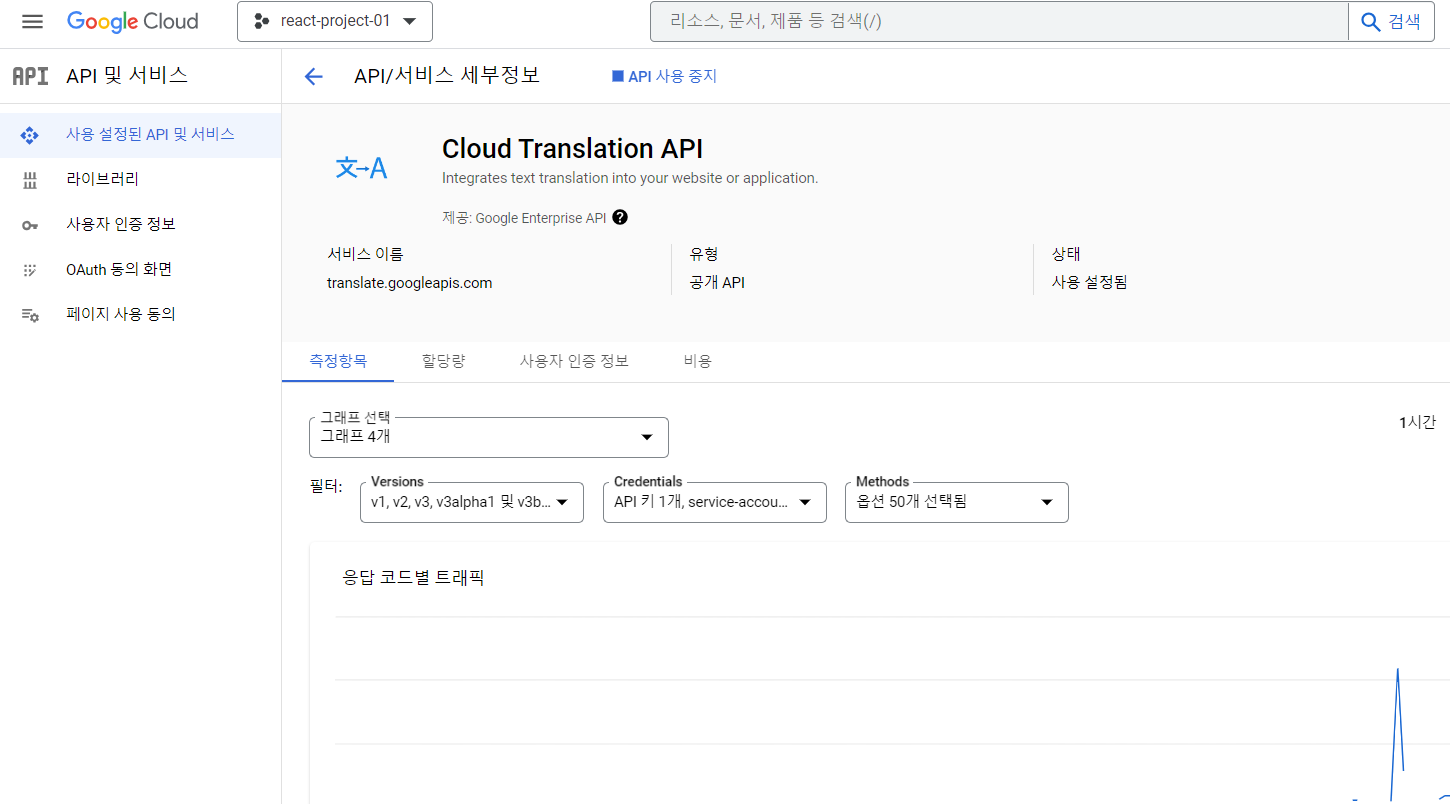
프로젝트를 하나 생성 후 Cloud Translation API 를 사용설정한다.
사용자 인증 정보 > 사용자 인증 정보 만들기 > API 키 생성한다.
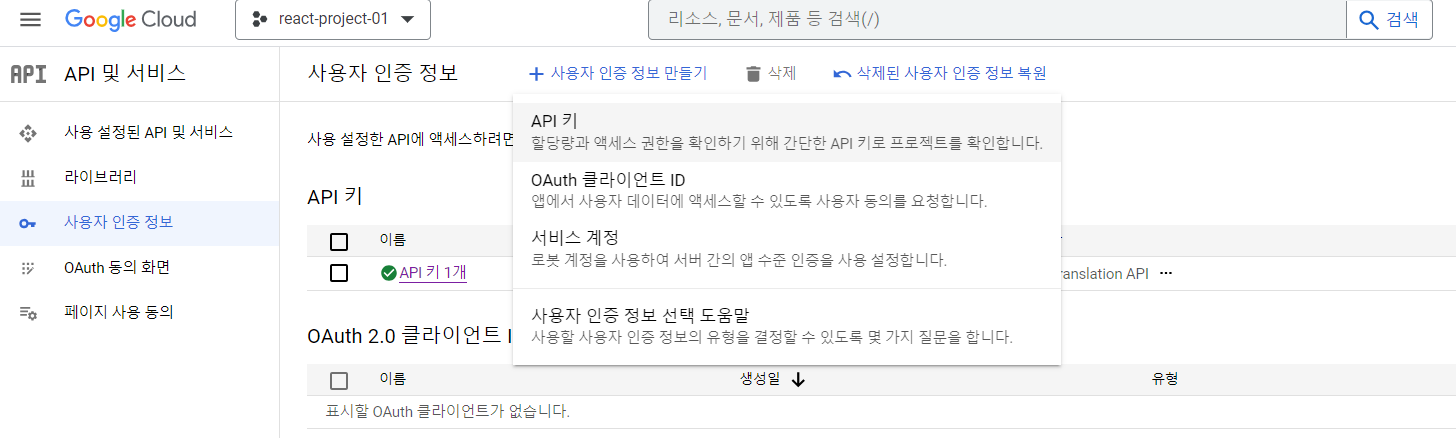
API Key 값을 복사해서 갖고 있는다.
API 키 수정을 통해 호출 제한 사항을 적절하게 설정한다.
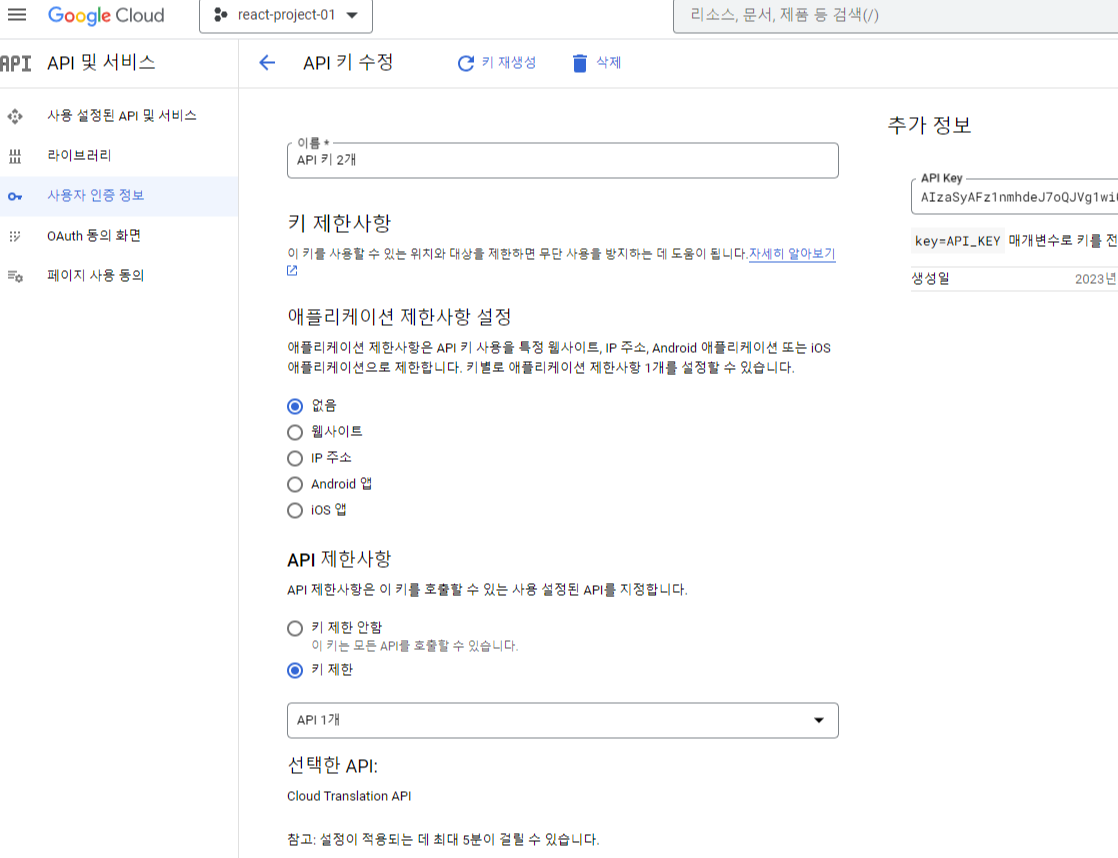
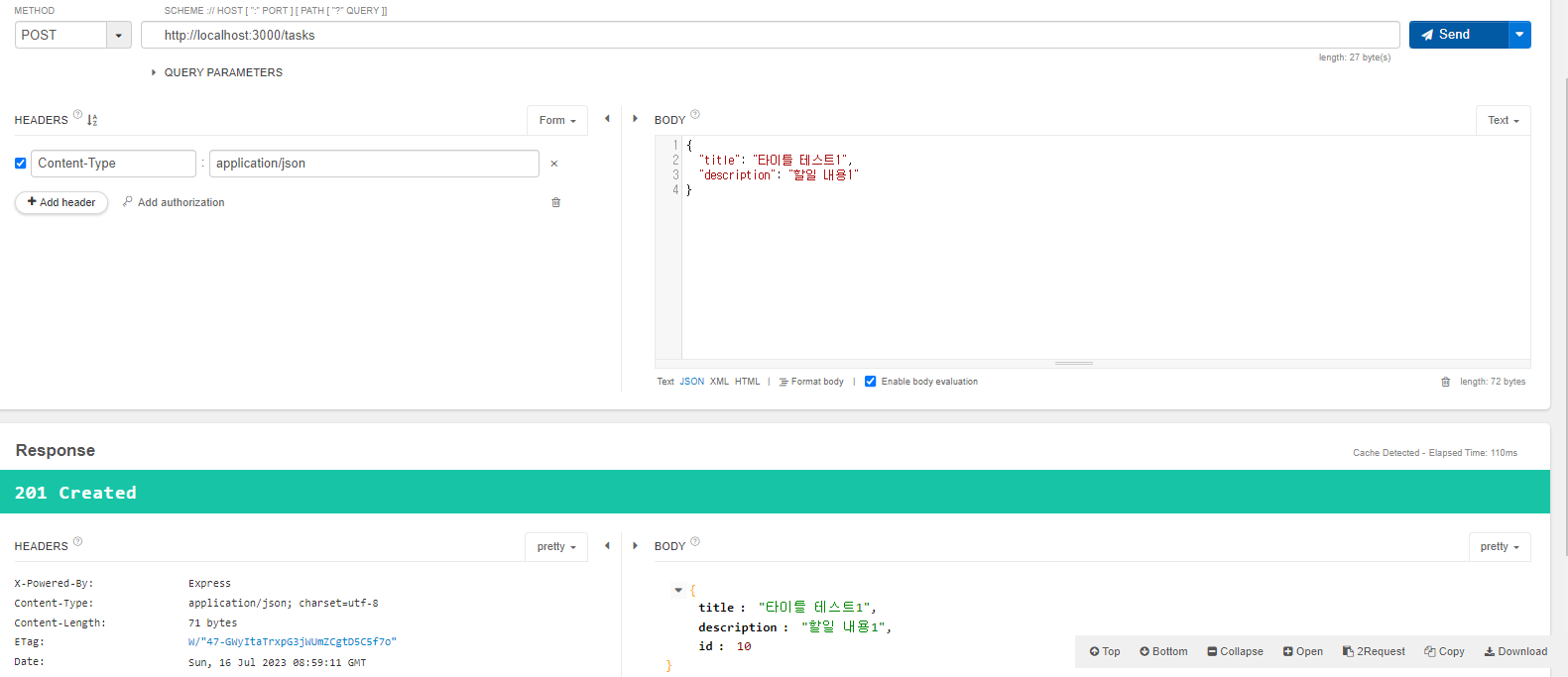
6. 구글 번역 API를 사용해 데이터를 번역해서 가져오자.
1 2 | # tailwindcss 설치 $ npm i @google-cloud/translate | cs |
6.1 먼저 퀴즈 객체 생성 후 데이터를 가져오자.
export interface Quiz {
category: string;
type: string;
difficulty: string;
question: string;
correct_answer: string;
incorrect_answers: string[];
all_answers: string[];
} const getQuizData = async() => {
let problemCnt = '1'
let url = `https://opentdb.com/api.php?amount=${problemCnt}&difficulty=easy&type=multiple`
let response = await fetch(url, {
method: 'GET',
});
let data = await response.json()
return data;
}
6.2 가져온 퀴즈 데이터를 인자로 받아 구글 번역 API를 불러 번역시킨다.
const translate = async (quizzes: Quiz[]) => {
let url = `https://translation.googleapis.com/language/translate/v2?key=${apiKey}`
multiplePreTranslate = '';
let preTranslate = '';
for(let quizObj of quizzes){
let icaListStr = '';
for (let ica of quizObj.incorrect_answers) {
if(ica === quizObj.incorrect_answers[quizObj.incorrect_answers.length - 1]) {
icaListStr += `${ica}`;
}else{
icaListStr += `${ica}\n`;
}
}
if(quizObj === quizzes[quizzes.length - 1]) {
preTranslate += `${quizObj.category}\n${quizObj.difficulty}\n${quizObj.question}\n${quizObj.correct_answer}\n${icaListStr}`;
}else{
preTranslate += `${quizObj.category}\n${quizObj.difficulty}\n${quizObj.question}\n${quizObj.correct_answer}\n${icaListStr}\n\n`;
}
}
multiplePreTranslate = dataStrReplace(preTranslate);
let response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
target: 'ko',
format: "text",
q: multiplePreTranslate
}),
});
let data = await response.json()
return data;
}
원활한 번역을 위해 문자열과 구분은 한줄내림(\n) 으로 구분해준다.
퀴즈데이터를 받아와 구글 번역 API를 통해 아래와 같이 데이터가 적절하게 번역된것을 확인할수 있다.
// 번역 전 퀴즈 데이터
`
Entertainment: Musicals & Theatres
medium
When was the play "Macbeth" written?
1606
1605
1723
1628
Entertainment: Musicals & Theatres
easy
Which Shakespeare play inspired the musical 'West Side Story'?
Romeo Juliet
Hamlet
Macbeth
Othello
`;
// 번역 후 퀴즈 데이터
`
엔터테인먼트: 뮤지컬 및 극장
중간
연극 "맥베스"는 언제 쓰여졌습니까?
1606년
1605년
1723년
1628년
엔터테인먼트: 뮤지컬 및 극장
쉬움
어떤 셰익스피어 연극이 뮤지컬 '웨스트 사이드 스토리'에 영감을 주었습니까?
로미오 줄리엣
작은 촌락
맥베스
오셀로
`;
7. 화면을 꾸며보자.
App.tsx
import React, { useLayoutEffect, useState } from 'react';
import './App.css';
import { Quiz } from './quiz.interface';
function App() {
const [translateQuizzArr, setTranslateQuizzArr] = useState<Quiz[]>([]);
const [currentQuizIndex, setCurrentQuizIndex] = useState<number>(0);
const [score, setScore] = useState<number>(0);
const [selectedAnswer, setSelectedAnswer] = useState<string | null>(null);
const [showAnswer, setShowAnswer] = useState<boolean>(false);
const [hasIncorrectAttempt, setHasIncorrectAttempt] = useState(false);
const [isCorrect, setIsCorrect] = useState(false);
const [quizTrigger, setQuizTrigger] = useState(false);
const [isLoading, setIsLoading] = useState(true);
const { REACT_APP_GOOGLE_TRANSLATE_API_KEY } = process.env;
const apiKey: string | undefined = REACT_APP_GOOGLE_TRANSLATE_API_KEY;
if (!apiKey) {
throw new Error('Missing Google API Key');
}
let multiplePreTranslate = '';
useLayoutEffect(() => {
getQuizData().then(response => {
console.log(response.data);
let quizzes: Quiz[] = response.results;
let quizArr: Quiz[] = [];
const translatePromises = translate(quizzes)
.then(response => {
let translatedData = response?.data?.translations[0]?.translatedText;
let multipleArrPreTranslate = translatedData.split('\n\n');
let multipleEngPreTranslate = multiplePreTranslate.split('\n\n');
for(let i=0; i < multipleArrPreTranslate.length; i++){
let data = multipleArrPreTranslate[i];
let engData = multipleEngPreTranslate[i];
let arrPreTranslate = data.split('\n');
let engArrPreTranslate = engData.split('\n');
let engRightAnswerStr = dataStrReplace(engArrPreTranslate[3]);
let engWrongAnswerStr1 = dataStrReplace(engArrPreTranslate[4]);
let engWrongAnswerStr2 = dataStrReplace(engArrPreTranslate[5]);
let engWrongAnswerStr3 = dataStrReplace(engArrPreTranslate[6]);
let incorrectStrArr: string[] = [];
let questionStr = `${dataStrReplace(arrPreTranslate[2])}`;
let rightAnswerStr = `${dataStrReplace(arrPreTranslate[3])} ( ${engRightAnswerStr} )`;
let wrongAnswerStr1 = `${dataStrReplace(arrPreTranslate[4])} ( ${engWrongAnswerStr1} )`;
let wrongAnswerStr2 = `${dataStrReplace(arrPreTranslate[5])} ( ${engWrongAnswerStr2} )`;
let wrongAnswerStr3 = `${dataStrReplace(arrPreTranslate[6])} ( ${engWrongAnswerStr3} )`;
incorrectStrArr.push(wrongAnswerStr1, wrongAnswerStr2, wrongAnswerStr3);
let allAnswersStrArr: string[] = [];
allAnswersStrArr.push(...incorrectStrArr, rightAnswerStr);
shuffleArray(allAnswersStrArr);
let translateQuizObj: Quiz = {
category: arrPreTranslate[0],
difficulty: arrPreTranslate[1],
question: questionStr,
correct_answer: rightAnswerStr,
incorrect_answers: incorrectStrArr,
all_answers: allAnswersStrArr,
type: ''
};
quizArr.push(translateQuizObj);
}
})
.catch(reason => {
console.log(reason.message);
return {
category: '',
difficulty: '',
question: '',
correct_answer: '',
incorrect_answers: [''],
type: ''
} as Quiz;
});
Promise.all([translatePromises]).then(() => {
setTranslateQuizzArr(quizArr);
setIsLoading(false);
});
});
// eslint-disable-next-line react-hooks/exhaustive-deps
}, [quizTrigger]);
const handleSolveMore = () => {
let quizArr: Quiz[] = [];
setTranslateQuizzArr(quizArr);
setIsLoading(true);
setQuizTrigger(!quizTrigger);
setScore(0);
setCurrentQuizIndex(0);
};
const handleAnswer = (answer: string) => {
setSelectedAnswer(answer);
const isAnswerCorrect = answer === translateQuizzArr[currentQuizIndex].correct_answer;
if (isAnswerCorrect) {
setIsCorrect(true);
if (!hasIncorrectAttempt) {
setScore(score + 1);
}
setShowAnswer(true);
setTimeout(() => {
setIsCorrect(false);
setShowAnswer(false);
setHasIncorrectAttempt(false);
setCurrentQuizIndex(currentQuizIndex + 1);
}, 800);
} else {
setShowAnswer(true);
setHasIncorrectAttempt(true);
}
};
function dataStrReplace(arrPreTranslate: any) {
return arrPreTranslate.replace(/"/g, '"')
.replace(/'/g, "'")
.replace(/“/g, '"')
.replace(/”/g, '"');
}
function shuffleArray(array: any[]) {
for (let i = array.length - 1; i > 0; i--) {
const j = Math.floor(Math.random() * (i + 1));
[array[i], array[j]] = [array[j], array[i]];
}
}
async function getQuizData() {
let problemCnt = '3'
let url = `https://opentdb.com/api.php?amount=${problemCnt}&difficulty=easy&type=multiple`
let response = await fetch(url, {
method: 'GET',
});
let data = await response.json()
return data;
}
async function translate(quizzes: Quiz[]) {
let url = `https://translation.googleapis.com/language/translate/v2?key=${apiKey}`
multiplePreTranslate = '';
let preTranslate = '';
for(let quizObj of quizzes){
let icaListStr = '';
for (let ica of quizObj.incorrect_answers) {
if(ica === quizObj.incorrect_answers[quizObj.incorrect_answers.length - 1]) {
icaListStr += `${ica}`;
}else{
icaListStr += `${ica}\n`;
}
}
if(quizObj === quizzes[quizzes.length - 1]) {
preTranslate += `${quizObj.category}\n${quizObj.difficulty}\n${quizObj.question}\n${quizObj.correct_answer}\n${icaListStr}`;
}else{
preTranslate += `${quizObj.category}\n${quizObj.difficulty}\n${quizObj.question}\n${quizObj.correct_answer}\n${icaListStr}\n\n`;
}
}
multiplePreTranslate = dataStrReplace(preTranslate);
let response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
target: 'ko',
format: "text",
q: multiplePreTranslate
}),
});
let data = await response.json()
return data;
}
return (
<div className="App bg-blue-50 min-h-screen flex flex-col items-center justify-center font-nanum-gothic font-bold">
<h1 className="text-4xl mb-4 font-bold">랜덤퀴즈 앱</h1>
{
isLoading ?
<div>Loading...</div> :
(
<h2 className="text-2xl mb-8">점수 : {score}</h2>
)
}
{translateQuizzArr.length > 0 && currentQuizIndex <= translateQuizzArr.length - 1 ? (
<div className="w-full bg-white p-8 rounded shadow flex flex-col">
<h2 className="text-xl mb-4">{translateQuizzArr[currentQuizIndex].question}</h2>
{translateQuizzArr[currentQuizIndex].all_answers.map((answer, index) => (
<button
key={index}
onClick={() => handleAnswer(answer)}
className={`my-2 p-4 text-white
${showAnswer && answer === translateQuizzArr[currentQuizIndex].correct_answer
? 'bg-green-500 text-white animate-pulse'
: showAnswer && answer === selectedAnswer
? 'bg-red-500 text-white'
: 'bg-sky-500/100 text-white'}`}
>
{answer}
</button>
))}
{isCorrect && (
<div className="bg-green-500 text-white p-4 mt-4 rounded">
정답입니다. 다음 문제로 이동 중...
</div>
)}
{showAnswer && !isCorrect && (
<div className="text-red-500 p-4 mt-4 rounded">
정답은 : {translateQuizzArr[currentQuizIndex].correct_answer} 입니다.
</div>
)}
</div>
) : isLoading ? <div>
<h2 className="text-2xl">랜덤 퀴즈 로딩 중입니다.</h2>
</div> :
(
<>
<h2 className="text-2xl">퀴즈가 끝났습니다. <br/> 최종 점수는 {score} 점 입니다.</h2>
<button className="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded mt-4" onClick={handleSolveMore}>
퀴즈 더 풀기
</button>
</>
)
}
</div>
);
}
export default App;
App.css
/* App.css */
@import 'tailwindcss/base';
@import 'tailwindcss/components';
@import 'tailwindcss/utilities';
@import url('https://fonts.googleapis.com/css2?family=Nanum+Gothic:wght@400;700;800;900&display=swap');
body {
@apply font-sans m-0 p-0 bg-gray-200;
}
.App {
@apply max-w-md mx-auto p-5 bg-white rounded-lg shadow-md;
}
h1 {
@apply text-blue-600 text-center;
}
.input-container {
@apply bg-blue-100 p-2 rounded mb-4;
@apply w-full mx-2 box-border;
}
input {
@apply w-full py-2 px-3 border-none outline-none text-lg rounded bg-blue-200 box-border;
}
.translated-text {
@apply text-lg leading-loose;
}
@media screen and (max-width: 600px) {
.App {
@apply p-2;
}
}
@media screen and (max-width: 400px) {
.App {
@apply p-1;
}
}
7.1 결과 화면

- 퀴즈는 한 사이클당 30문제로 구성된다.
- 퀴즈를 푸는 사용자는 사지선다로 문제를 풀수 있다
- 최초 정답 선택 시 점수가 올라간다.
- 최초 틀린 문제를 선택 시 점수가 올라가지 않고 정답을 알려준다.
- 정답을 선택 시 다음 문제로 진입할 수 있다.
- 퀴즈 주제 바꾸기로 퀴즈 카테고리를 바꿀수 있다.
8. 문제가 생겼다. 구글 클라우드 번역 API는 공짜가 아니다.
하루에 요청가능한 글자수와 건수가 정해져있다. ( 프로젝트가 결제설정 되어있다면 사용한 만큼 지불된다)
https://cloud.google.com/translate/pricing?hl=ko
가격 책정 | Cloud Translation | Google Cloud
Cloud Translation 가격 책정 검토
cloud.google.com
https://cloud.google.com/billing/docs/how-to/modify-project?hl=ko#how-to-disable-billing
프로젝트의 결제 사용 설정, 사용 중지, 변경 | Cloud Billing | Google Cloud
의견 보내기 프로젝트의 결제 사용 설정, 사용 중지, 변경 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. 이 페이지에서는 각 Google Cloud 프로젝트와 Google Maps
cloud.google.com
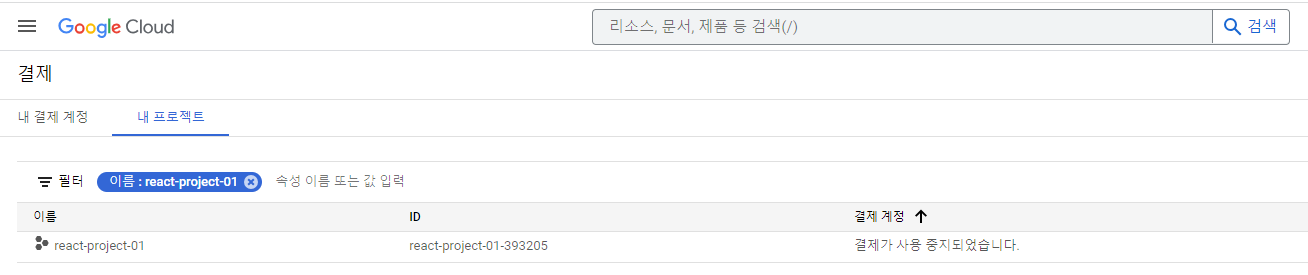
사용량을 초과하면 아래와 같이 에러가 발생될 것이다.
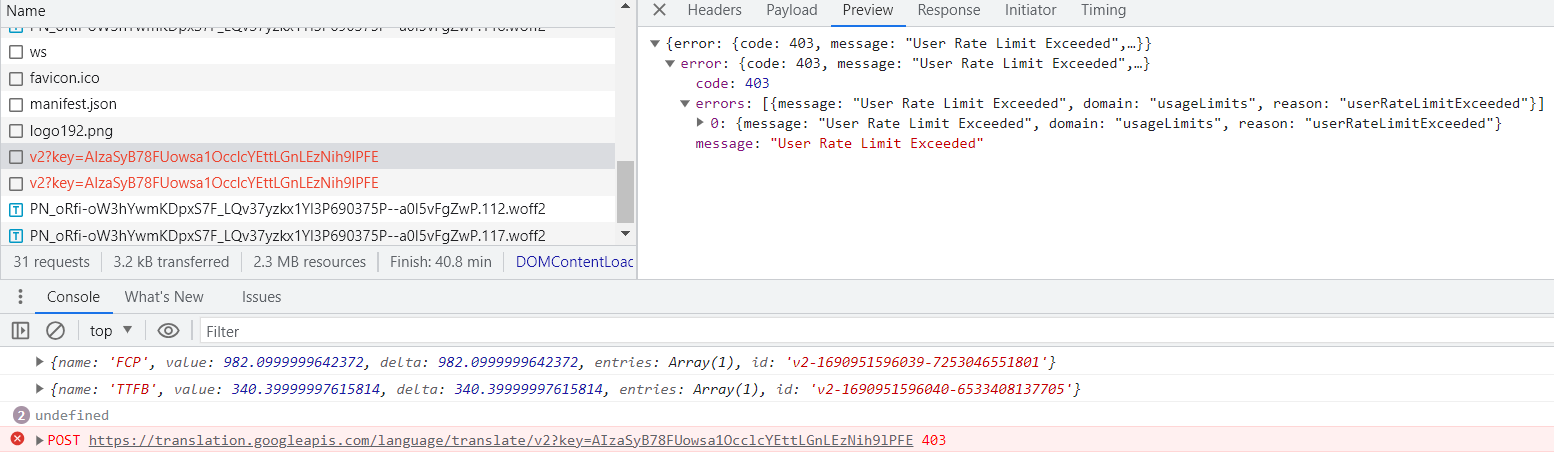
User Rate Limit Exeeded !!!! (허허 ... 흙발자 무시하는겁니가... ㅠㅠ)
퀴즈 데이터는 카테고리가 약 24개이고 40문제씩 호출할 수 있었다.
그럼 총 문제수만 8~900 개 일 것이다.
퀴즈 오픈 API도 분명 데이터가 추가되거나 업데이트 될텐데...
1. 매번 앱 실행 시 구글 번역 API를 실행해야한다?
-> 번역 API 트래픽 다량 발생가능성 높음. 얼마나 번역할것인가?
새로운 퀴즈 데이터에 대한 업데이트나 추가 갱신이 빠름
2. 처음 불러올때 데이터를 조금만 불러온다 ?
-> 퀴즈데이터 번역하는 시간 또한 고려해야하니 유저입장에서 다음화면으로 가기전까지 피곤할것이다.
번역 API 트래픽은 줄었지만 발생한다.
3. 대량의 데이터를 한번에 번역해서 파일형태의 static으로 갖고있는다?
-> 퀴즈 데이터 최신화 업데이트에 대한 문제
일단 비용이 발생하면 부담이 발생될것 같아 3번으로 고치겠다.
8.1 퀴즈 데이터 static 파일 만들기
quizData.tsx
export const ENG_QUIZ_CATE9 =
`
General Knowledge
easy
What is the official language of Brazil?
Portugese
Brazilian
Spanish
English
`;
export const KOR_QUIZ_CATE9 =
`
일반 지식
쉬움
브라질의 공식 언어는 무엇입니까?
포르투갈어
브라질
스페인의
영어
`;
영어 원문 데이터, 한글 번역된 데이터 2개를 갖고 static 데이터를 불러와 활용하고 있다.
App.tsx
const getStaticQuizData = () => {
let quizArr: Quiz[] = [];
let quizCategory = [
{"eng": ENG_QUIZ_CATE9, "kor" : KOR_QUIZ_CATE9}
, {"eng": ENG_QUIZ_CATE10, "kor": KOR_QUIZ_CATE10}
]
shuffleArray(quizCategory);
for(let data=0; data < quizCategory.length; data++){
let quizCate = quizCategory[data];
let multipleArrPreTranslate = quizCate.kor.split('\n\n');
let multipleEngPreTranslate = quizCate.eng.split('\n\n');
for(let i=0; i < multipleArrPreTranslate.length; i++){
let data = multipleArrPreTranslate[i];
let engData = multipleEngPreTranslate[i];
let arrPreTranslate = data.split('\n');
let engArrPreTranslate = engData.split('\n');
let engRightAnswerStr = dataStrReplace(engArrPreTranslate[3]);
let engWrongAnswerStr1 = dataStrReplace(engArrPreTranslate[4]);
let engWrongAnswerStr2 = dataStrReplace(engArrPreTranslate[5]);
let engWrongAnswerStr3 = dataStrReplace(engArrPreTranslate[6]);
let incorrectStrArr: string[] = [];
let questionStr = `${dataStrReplace(arrPreTranslate[2])}`;
let rightAnswerStr = `${dataStrReplace(arrPreTranslate[3])} ( ${engRightAnswerStr} )`;
let wrongAnswerStr1 = `${dataStrReplace(arrPreTranslate[4])} ( ${engWrongAnswerStr1} )`;
let wrongAnswerStr2 = `${dataStrReplace(arrPreTranslate[5])} ( ${engWrongAnswerStr2} )`;
let wrongAnswerStr3 = `${dataStrReplace(arrPreTranslate[6])} ( ${engWrongAnswerStr3} )`;
incorrectStrArr.push(wrongAnswerStr1, wrongAnswerStr2, wrongAnswerStr3);
let allAnswersStrArr: string[] = [];
allAnswersStrArr.push(...incorrectStrArr, rightAnswerStr);
shuffleArray(allAnswersStrArr);
let translateQuizObj: Quiz = {
category: arrPreTranslate[0],
difficulty: arrPreTranslate[1],
question: questionStr,
correct_answer: rightAnswerStr,
incorrect_answers: incorrectStrArr,
all_answers: allAnswersStrArr,
type: ''
};
quizArr.push(translateQuizObj);
}
}
setTranslateQuizzArr(quizArr);
setIsLoading(false);
}
결국 API를 활용하지 않았으니 속도는 빨라졌다.
최신 데이터에 대한 업데이트는 주기적으로 API를 호출하여
기존 데이터와 비교하여 변경사항에 대한 정보를 받아올지 생각해봐야한다.
마지막으로 배포된 url과 github 주소이다.
https://shlee0882.github.io/react-ts-quiz-app/
랜덤퀴즈 앱
shlee0882.github.io
https://github.com/shlee0882/react-ts-quiz-app
GitHub - shlee0882/react-ts-quiz-app: :question: ReactJs, Ts, Tailwindcss 랜덤 퀴즈 앱 토이 프로젝트
:question: ReactJs, Ts, Tailwindcss 랜덤 퀴즈 앱 토이 프로젝트 - GitHub - shlee0882/react-ts-quiz-app: :question: ReactJs, Ts, Tailwindcss 랜덤 퀴즈 앱 토이 프로젝트
github.com
react-ts-quiz-app의
dev 브랜치에 퀴즈 데이터가 static으로 변경된 소스가 올라가있다.
master 브랜치에는 구글 번역 api가 적용된 소스가 올라가있다.
https://github1s.com/shlee0882/react-ts-quiz-app
GitHub1s
github1s.com
이상으로 포스팅을 마치겠다.
'전체 > 개인 프로젝트' 카테고리의 다른 글
| ReactJs, TypeScript, Vite 휴가 추천 토이 프로젝트 (2) | 2023.06.10 |
|---|