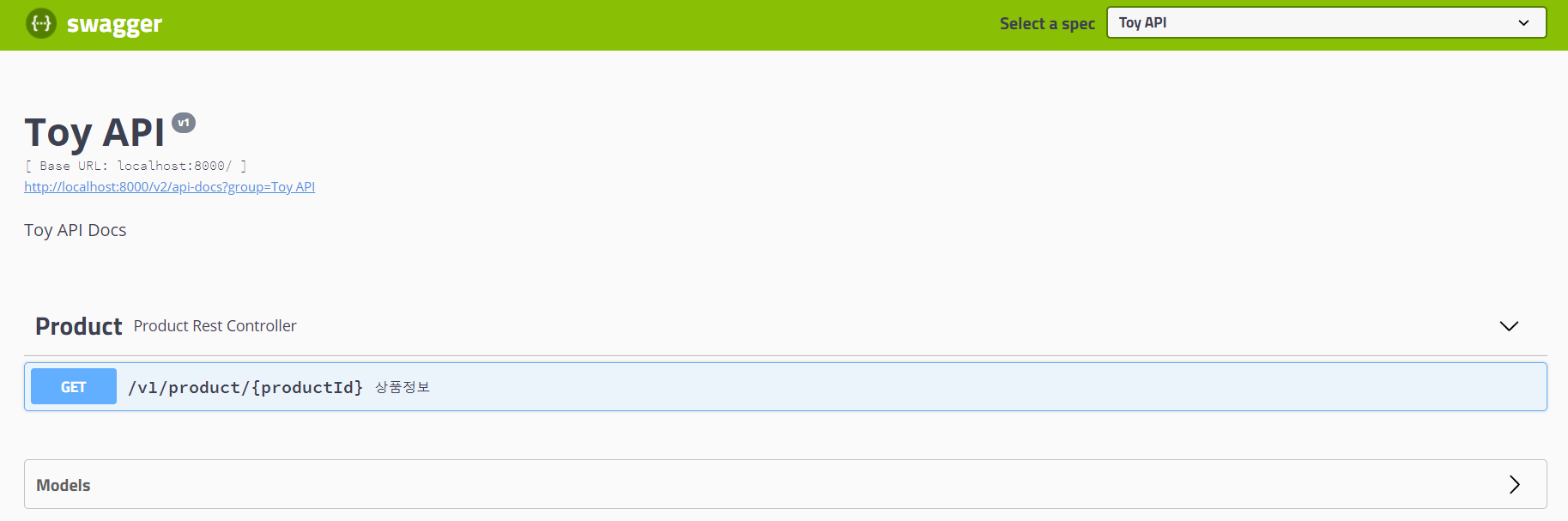
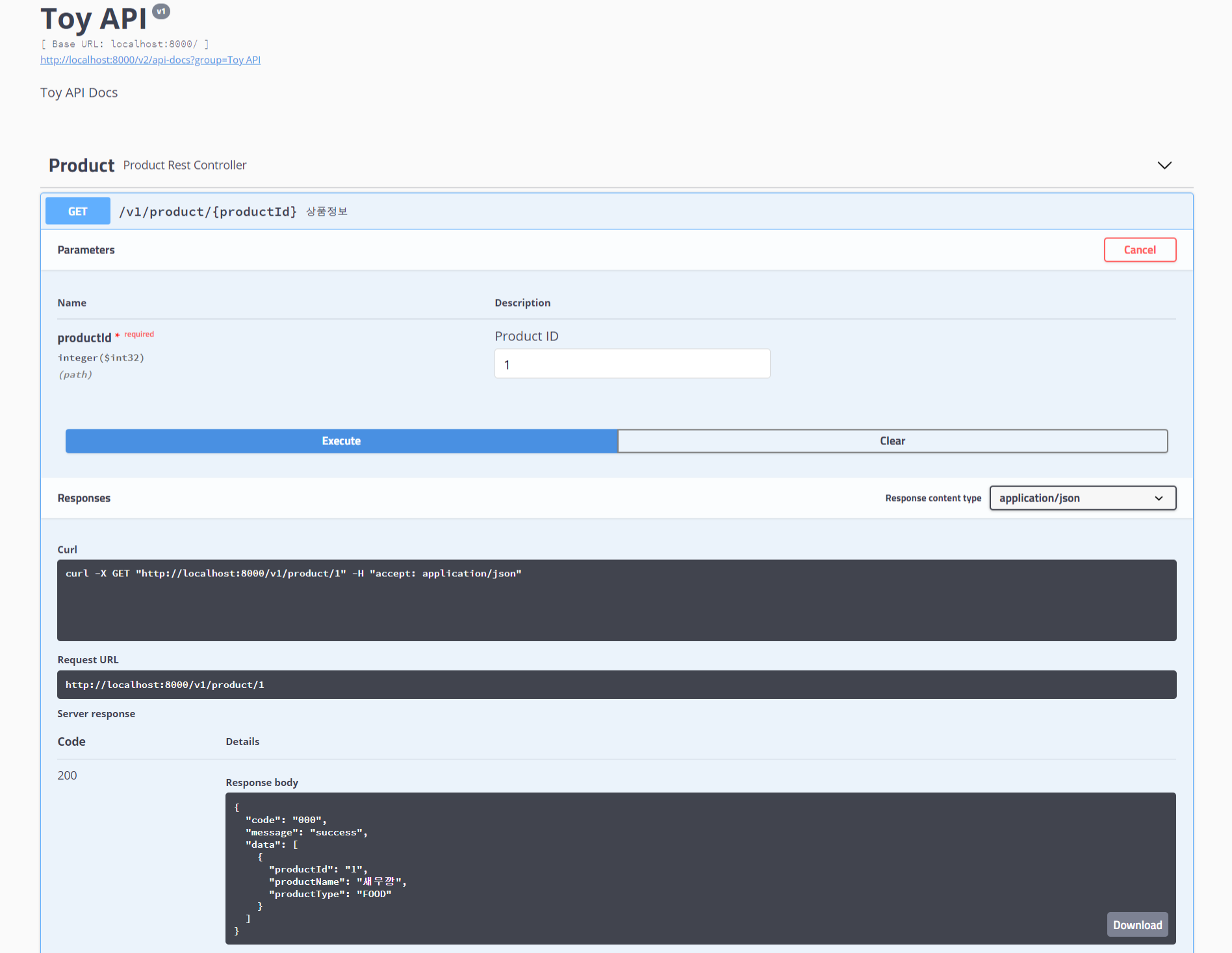
1. SQL 쿼리를 자바로 표현하기
SQL 질의 언어에서 조건절을 작성하여
칼로리가 400 이하인 음식의 이름을 아래 쿼리처럼 뽑을 수 있다.
| SELECT a.name FROM DISHES a WHERE a.calorie < 400 ; | cs |
위 쿼리와 마찬가지로 자바 컬렉션으로도 비슷한 기능을 만들 수 있다.
아래 코드는 스트림을 이용하여 칼로리가 400 이하인 음식을 정렬하여 이름을 리스트로 뽑고 있다.
스트림을 이용하면 멀티스레드 코드를 구현하지 않아도 데이터를 투명하게 병렬로 처리 할 수 있다.
| public static List<String> getLowCaloricDishesNames(List<Dish> dishes) { List<String> list = dishes.stream() .filter(a -> a.getCalories() < 400) .sorted(Comparator.comparing(Dish::getCalories)) .map(Dish::getName) .collect(Collectors.toList()); return list; } | cs |
2. 스트림 API 특징은 다음과 같다.
- 선언형 : 더 간결하고 가독성이 좋아진다.
- 조립할수 있음 : 유연성이 높아진다.
- 병렬화 : 성능이 좋아진다.
3. 스트림이란 뭘까?
스트림이란 "데이터 처리 연산을 지원하도록 소스에서 추출된 연속된 요소(Sequence of elements)"로 정의할 수 있다.
데이터의 연속된 요소를 관리하는 것은 컬렉션에서 처리하는데?
컬렉션은 시간과 공간의 복잡과 관련된 요소 저장 및 접근 연산이 주를 이루고
스트림은 filter, sorted, map 처럼 계산식이 주를 이룬다.
스트림은 filter, map, reduce, find, math, sort 등으로 데이터를 조작할수 있다.
스트림은 파이프라이닝의 특징을 갖고 있다.
대부분의 스트림 연산은 스트림 연산끼리 연결해서 커다란 파이프라인을 구성할 수 있도록 스트림 자신을 반환한다.
게으름, 쇼트서킷 같은 최적화도 얻을 수 있다.
4. 컬렉션과 스트림의 차이가 뭘까?
DVD에 영화가 저장되어 있다고 하면 DVD는 컬렉션이다.
인터넷 스트리밍으로 같은 영화를 시청한다고 하자.
데이터를 언제 계산하느냐가 컬렉션과 스트림의 가장 큰 차이이다.
컬렉션은 현재 자료구조가 포함하는 모든 값을 메모리에 저장하는 구조이다.
반면 스트림은 요청할떄만 요소를 계산하는 고정된 자료구조이다.
(스트림에 요소를 추가하거나 스트림에서 요소를 제거 할 수 없다.)
반복자와 마찬가지로 스트림도 한번만 탐색 할 수 있다.
탐색된 스트림의 요소는 소비된다.
아래는 stream을 foreach로 반복하며 단어를 뽑아내는데
아래쪽 같은 foreach는 IllegalStateException error가 발생한다.
| List<String> names = Arrays.asList("Java8", "Lambdas", "In", "Action"); Stream<String> s = names.stream(); s.forEach(System.out::println); s.forEach(System.out::println); // IllegalStateException error | cs |
스트림은 아래와 같이 중간 연산, 최종 연산으로 이루어진다.
| public static List<String> getLowCaloricDishesNames(List<Dish> dishes) { List<String> list = dishes.stream() // 스트림 얻기 .filter(a -> a.getCalories() > 300) // 중간 연산 .map(Dish::getName) // 중간 연산 .limit(3) // 중간 연산 .collect(Collectors.toList()); // 최종 연산 return list; } | cs |
filter, map, limit는 서로 연결되어 파이프라인을 형성하고 collect로 파이프라인을 실행한 다음에 담게 된다.
중간 연산의 중요한 특징은 단말 연산을 스트림 파이프라인에 실행하기 전까지는 아무 연산도 수행하지 않는다는 것,
즉 게으르다는 것(lazy) 이다.
중간 연산을 합친 다음에 합쳐진 중간연산을 최종연산으로 한번에 처리하기 때문이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | public static List<String> getLowCaloricDishesNames(List<Dish> dishes) { List<String> list = dishes.stream() .filter(a -> { System.out.println("filtering: " + a.getName()); return a.getCalories() > 300; }) // 필터한 요리명 출력 .map(a -> { System.out.println("mapping: "+a.getName()); return a.getName(); }) // 추출한 요리명 출력 .limit(3) .collect(Collectors.toList()); System.out.println(list); return list; } | cs |
위 코드는 각 중간연산의 실행결과가 어떻게 진행되는지 확인해볼수 있는 코드이다.
실행하면 아래와 같은 결과가 나타난다.
| filtering: pork mapping: pork filtering: beef mapping: beef filtering: chicken mapping: chicken [pork, beef, chicken] | cs |
결과를 보면 300 칼로리가 넘는 음식은 여러개지만 처음에 3개만 선택되었고 filter와 map은 서로다른 연산이지만
한과정으로 병합되었다.
5. 스트림에서 가장 많이 사용되는 map() 이란 무엇일까?
스트림은 함수를 인수로 받는 map 메서드를 지원한다.
인수로 제공된 함수는 각 요소에 적용되며 함수를 적용한 결과가 새로운 요소로 매핑된다.
새로운 버전을 만든다는 개념에 가깝다.
변환에 가까운 매핑이라는 단어를 사용한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | List<Dish> menu = Dish.menu; List<String> dishNames = menu.stream() .map(Dish::getName) .collect(toList()); System.out.println(dishNames); // [pork, beef, chicken, french fries, rice, season fruit, pizza, prawns, salmon] List<String> words = Arrays.asList("Hello", "World"); List<Integer> wordLengths = words.stream() .map(String::length) .collect(toList()); System.out.println(wordLengths); // [5,5] List<String> uniqueChar = words.stream() .map(w -> w.split("")) // 배열 변환 .flatMap(Arrays::stream) // 생성된 스트림을 하나의 스트림으로 평면화 .distinct() .collect(Collectors.toList()); System.out.println(uniqueChar); // [H, e, l, o, W, r, d] | cs |
새롭게 변환해서 가져오겠다 라는 뜻이다.
map으로 연산한 결과를 하나의 스트림으로 평면화할때 flatMap을 사용한다.
6. 스트림에서 검색과 매칭을 확인할때는?
특정 속성이 데이터 집합에 있는지 여부를 검색하는 데이터 처리도 자주 사용되는데
스트림 API는 allMatch, anyMatch, noneMatch, findFirst, findAny ... 등 메서드를 제공한다.
프레디케이트가 주어진 스트림에서 적어도 한 요소와 일치하는지 확인할때
anyMatch 메서드를 사용한다.
| private static boolean isVegetarian() { return menu.stream() .anyMatch(Dish::isVegetarian); } | cs |
allMatch는 모든 요소가 주어진 프레디케이트와 일치하는지 검사한다.
| private static boolean isLowCalory() { return menu.stream() .allMatch(d -> d.getCalories() < 1000); } | cs |
noneMatch는 주어진 프레디케이트와 일치하는 요소가 없는지 확인한다.
| private static boolean isHighCalory() { return menu.stream() .noneMatch(d -> d.getCalories() >= 1000); } | cs |
findAny는 임의의 요소를 반환한다.
| private static Optional<Dish> findAnyVegeDish() { return menu.stream() .filter(Dish::isVegetarian) .findAny(); } | cs |
findFirst는 첫번째 요소를 반환한다.
| private static Optional<Dish> findFirstDish() { return menu.stream() .filter(Dish::isVegetarian) .findFirst(); } | cs |